
How AWS Internal Architecture Is Built – And What the Recent Outage Revealed About Its Hidden Dependencies
The recent AWS outage wasn’t particularly dramatic for us - our impact was minimal, close to zero downtime. This is something to deep dive into for another day. What was fascinating wasn’t the outage itself - it was what the incident report forced AWS to “leak” - its internal dependencies between services, which can shed some light on how AWS operates behind the scenes.
In this article, I want to dig into what AWS “leaked” through their own postmortem: their internal dependencies, the architectural patterns they use, and what we can learn from it about resilience design at massive scale.

Are you with AWS? Please correct me if I misunderstood anything - I’d love to get it right.
Here’s a graph that shows it all:
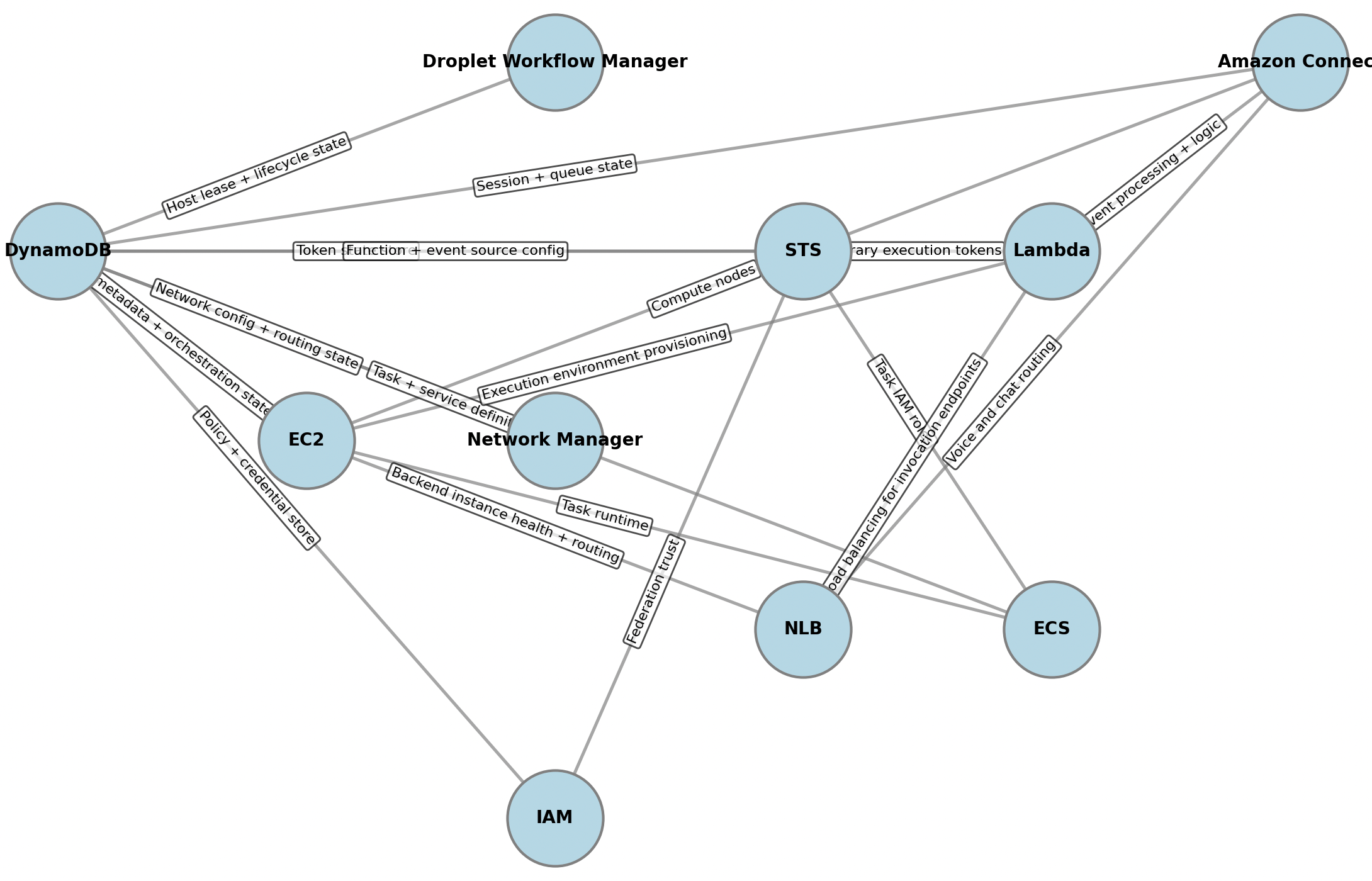
The heart of it all: DynamoDB
It’s no secret that some AWS services are more “foundational” than others.
EKS clearly depends on EC2 (Elastic Kubernetes Service runs on Elastic Compute Cloud).
Most serverless compute products (Lambda, Fargate, etc.) ultimately sit on EC2 as well - which the outage confirmed.
But what surprised me most was how deeply AWS itself depends on DynamoDB.
In my mind, DynamoDB was always a strong but “supporting” service - one of many NoSQL options alongside DocumentDB, ElastiCache, or MemoryDB.
Apparently, that’s not the case.
The postmortem revealed DynamoDB as a core control-plane datastore for AWS - a kind of global coordination layer that everything else builds on top of.
From the report, we can infer that DynamoDB is used internally to manage:
- The mapping between physical servers and EC2 instances
- Network configuration and state propagation for EC2
- Lambda creation, configuration, and invocation
- Amazon Connect session and queue state
- STS (Security Token Service) token generation
- AWS Console sign-ins and IAM authentication
- Redshift query processing orchestration - the fact that DynamoDB is used to facilitate query execution from another DB amazes me
- Fargate task launches

When you think about it, it’s remarkable how much AWS relies on DynamoDB — especially considering that EC2 was launched six years before DynamoDB even existed.
It suggests that AWS originally used a different control-plane datastore for orchestration and later migrated critical infrastructure to DynamoDB as it matured.
Another fascinating implication is that DynamoDB itself probably doesn’t run on EC2, since EC2 depends on it.
That raises a thought-provoking question:
If EC2 relies on DynamoDB, but DynamoDB can’t rely on EC2 — where does DynamoDB actually run?
The compute king - EC2
This comes as no surprise — EC2 is the foundational compute layer of AWS. Practically everything else runs on top of it.
From this incident, we can now confirm that Lambda and Fargate also operate on EC2 infrastructure behind the scenes.
But this level of interdependence really makes you think: was it the right architectural choice?
When so many core services rely on one another, even a small failure can cascade into a region-wide outage.
If DynamoDB — the service that underpins so many of AWS’s internal systems — were to go down for a few days, a large portion of the Internet could effectively go dark.
We’re not AWS, but there’s a valuable lesson here:
Don’t put all your eggs in one basket.
Design for resilience. Understand your critical dependencies. Build fault tolerance, even for your control plane.
Think about the chain reaction that AWS customers faced during this event — the wave of cascading errors, the operational chaos, and the engineering effort needed just to bring systems back to a stable state.
If this can happen at AWS scale, it’s a reminder that resilience isn’t something you bolt on later — it’s part of the architecture from day one.
Here comes what I’m working on — a platform that helps you build fault-tolerant backends by mapping dependencies, enforcing policies, and preventing cascading failures.
Sidenote - The internallity of it all
Something to think about: if Fargate relies on EC2 for compute, and EC2 itself relies on DynamoDB to manage networking and physical server mappings, that implies there are EC2 instances running that aren’t tied to any customer account.
From a security perspective, that’s a fascinating thought — if someone ever managed to breach one of those internal EC2 hosts, they could theoretically get unlimited compute, for free!
What do you think of this? Please LMK!