PostgreSQL Indexes Demystified: A Deep Dive Into Efficiency and Optimization
PostgreSQL Indexes Demystified: A Deep Dive into Efficiency and Optimization
Introduction
PostgreSQL, often referred to as Postgres, is a powerful and popular open-source relational database management system. One of its key features that contributes to its efficiency and performance is the use of indexes. In this blog post, we will delve into the world of PostgreSQL indexes, exploring their types, functionality, impact, and optimization techniques.
Understanding Indexes
At its core, an index is a data structure that enhances the speed of data retrieval operations on a database table. It acts like a roadmap, allowing the database engine to quickly locate rows that match certain criteria, such as filtering, sorting, and grouping. Indexes can have a significant impact on memory usage, CPU utilization, and overall query performance. However, not all queries utilize indexes, and it’s crucial to understand when and how to use them effectively.
However, they also come with trade-offs. These include increased storage requirements, potential write operation slowdowns due to maintenance, complexity in managing multiple indexes, challenges in selecting the right index type, and the need for periodic optimization. Additionally, bulk operations and backups can be influenced in performance. To leverage the advantages of indexes while mitigating these drawbacks, careful planning, monitoring, and maintenance are essential.
Types of Indexes
B-TREE (Balanced Tree)
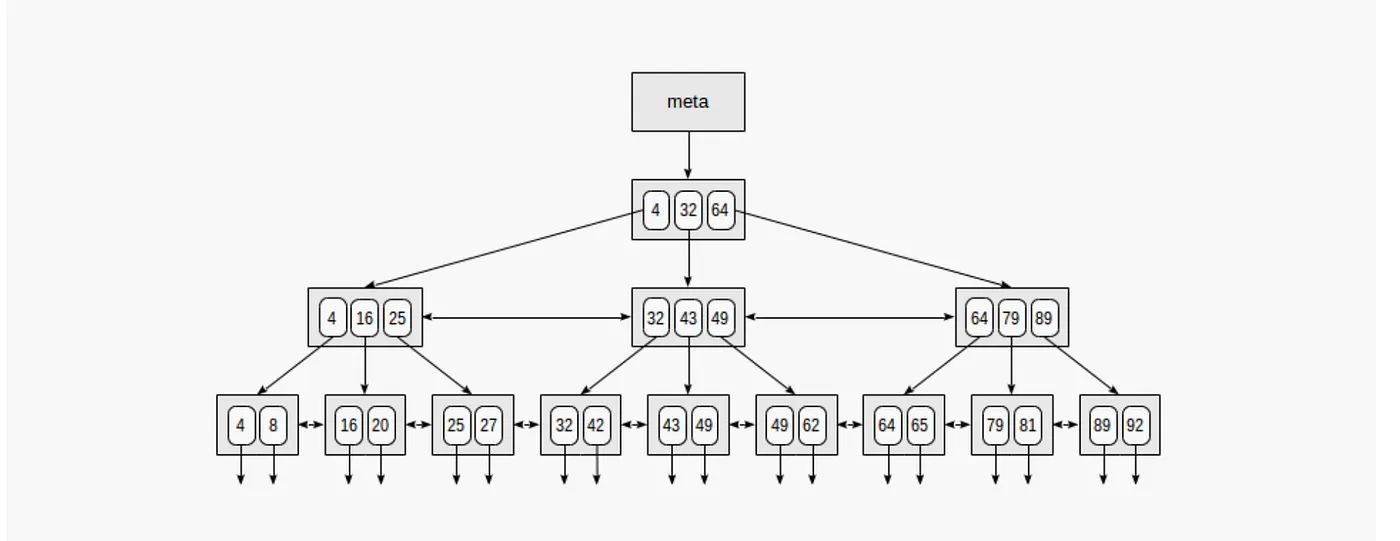
The B-tree index is the default index type in PostgreSQL. It’s a balanced tree structure that supports filtering, sorting, and grouping operations efficiently. B-tree indexes are particularly useful for equality and range queries. Since this is the default index and it’s probably the one you’ll want to use, we’ll deep dive into this index type.
GIN (Generalized Inverted Index)
Similar to B-tree, GIN indexes support arrays and can be used for complex queries involving array operations. They are suitable for scenarios where you need to search within array, lexeme or tsvector types.
HASH
HASH indexes facilitate one-to-one relationships between keys and values. They are useful for accessing specific items by values other than primary keys, in a faster manner compared to B-tree. However, HASH indexes do not support ordering, filtering, or grouping.
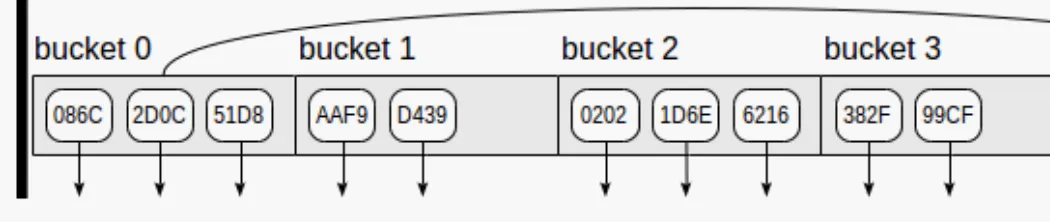
BRIN (Block Range Index)
BRIN indexes are designed for handling large datasets with static ranges. They are suitable for accessing data within specific ranges, such as IP addresses or timestamps. BRIN indexes optimize storage by focusing on blocks of data rather than individual rows.
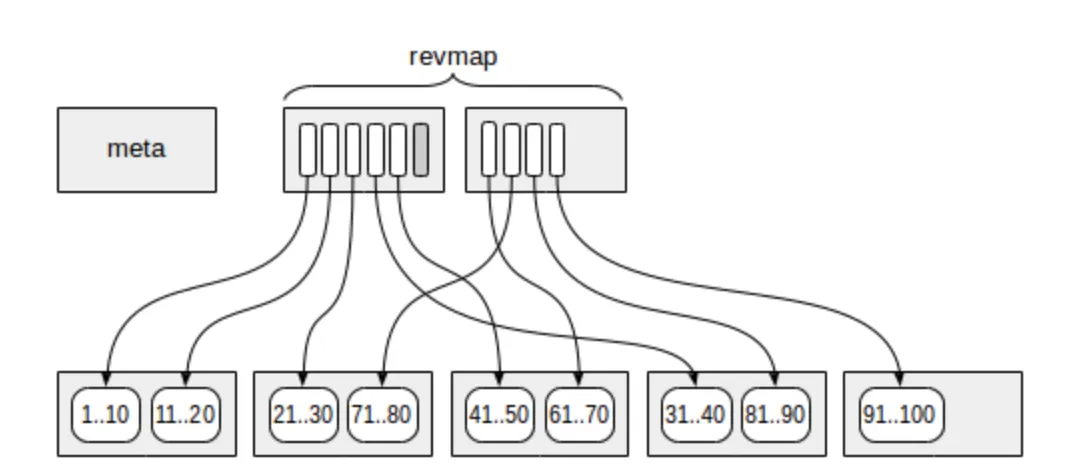
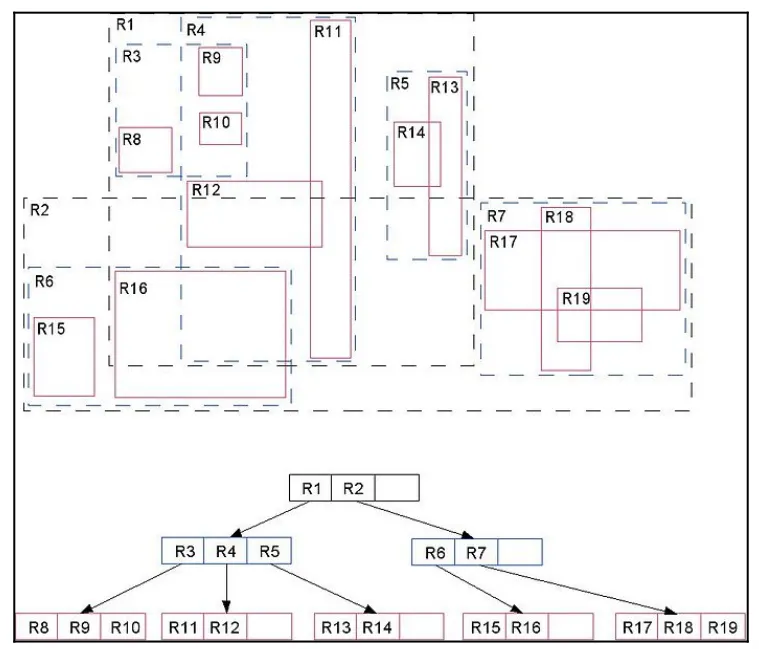
GiST/SP-GiST (Generalized Search Tree/Space-Partitioned Generalized Search Tree)
These indexes are designed for handling complex data types and spatial data. They enable efficient searching and retrieval operations on specialized data structures like geometric shapes and textual data.
Deep Dive into B-Tree Indexes
To illustrate how indexes work, and since it’s probably the index to use, let’s focus on the B-tree index type. PostgreSQL provides powerful tools for analyzing query execution plans:
- EXPLAIN: This command displays the query execution plan, showing how PostgreSQL intends to execute a query.
- EXPLAIN ANALYZE: This command not only explains the plan but also executes the query and provides detailed performance statistics.
Example Scenario: Indexing Storm Data
Imagine a scenario where we have weather data stored in a table. We want to efficiently retrieve information about storms, sort them by event type, and analyze the impact on crops. We create a B-tree index on the event type and damage to crops columns to optimize our queries.
However, while B-tree indexes are efficient for filtering, sorting, and grouping, they might not always provide optimal performance when it comes to ordering data within a filter. In such cases, the database might require additional sorting steps.
Let’s explore some queries and see the way we can improve them.
Indexing WHERE Statement
Let’s say we want to retrieve all of the events of ‘Winter Storm’ that happened, we’ll start by writing the query and run it with EXPLAIN ANALYZE to understand the planner decisions:
EXPLAIN ANALYZE SELECT * FROM weather WHERE event_type = 'Winter Storm';
Seq Scan on weather (cost=0.00..115.00 rows=11 width=622) (actual time=0.100..19.800 rows=11 loops=1)
Filter: ((event_type)::text = 'Winter Storm'::text)
Rows Removed by Filter: 1189
Planning Time: 30.000 ms
Execution Time: 20.800 ms
(5 rows)
We can see that the planner chose the “Seq Scan” option, which means it’s going to load all of the table data into the memory and search one by one. This approach is not efficient and may be slow in large tables.
Let’s try to index the “event_type” field and see what happens:
CREATE INDEX idx_weather_type ON weather(event_type);
Bitmap Heap Scan on weather (cost=4.36..37.56 rows=11 width=622) (actual time=0.500..2.300 rows=11 loops=1)
Recheck Cond: ((event_type)::text = 'Winter Storm'::text)
Heap Blocks: exact=6
-> Bitmap Index Scan on idx_weather_type (cost=0.00..4.36 rows=11 width=0) (actual time=0.400..0.400 rows=11 loops=1)
Index Cond: ((event_type)::text = 'Winter Storm'::text)
Planning Time: 23.300 ms
Execution Time: 7.200 ms
(7 rows)
The default index type is BTREE so it’ll be chosen if you do not provide the type to the CREATE INDEX command.
Now the query will be optimized since it used the index in order to find the “event_type”, the query will be like this:
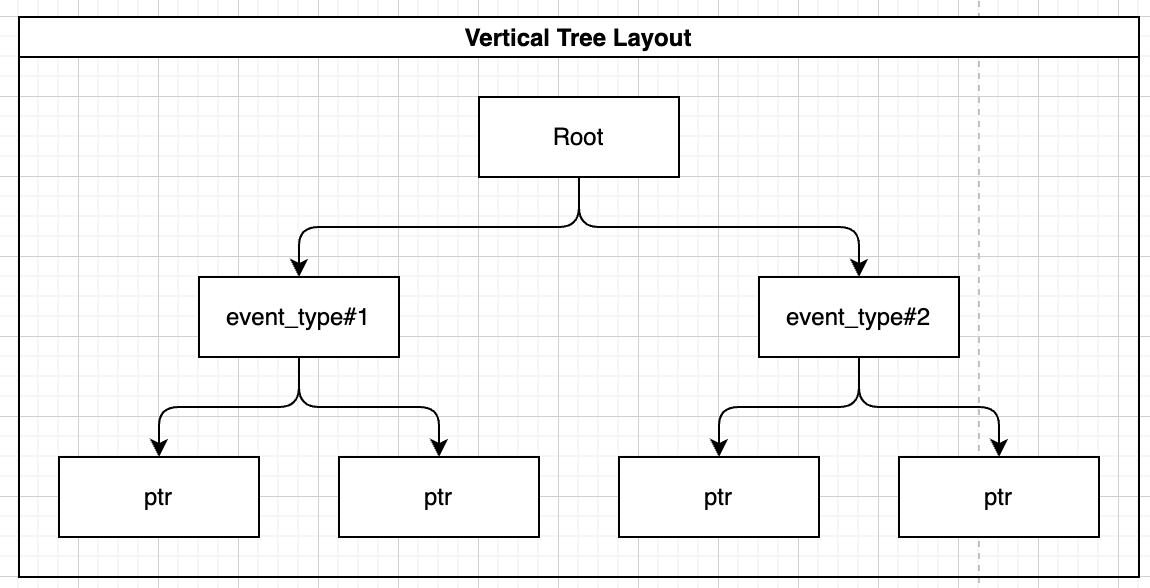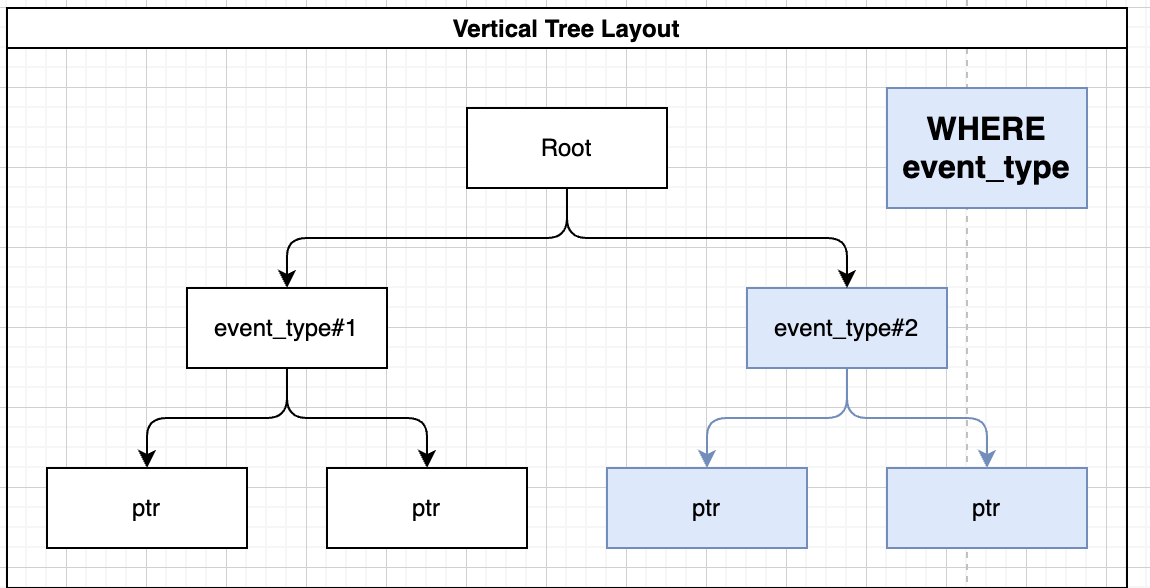
You can also index several fields, for example if you want to query both “event_type” and “damage_crops” you can index the data in the following way:
CREATE INDEX idx_storm_crop ON weather (event_type, damage_crops);
NOTE! The order of the index is very important, the “event_type” will be indexed before the “damage_crops”, so you’ll be able to use this index to run the previous query and to query for only “event_type”, but you won’t be able to query only damage_crops since it’s not available at root level.
Let’s run this query:
SELECT * FROM weather WHERE event_type = 'Winter Storm' AND damage_crops > 0;
Using the index the query will look like this:
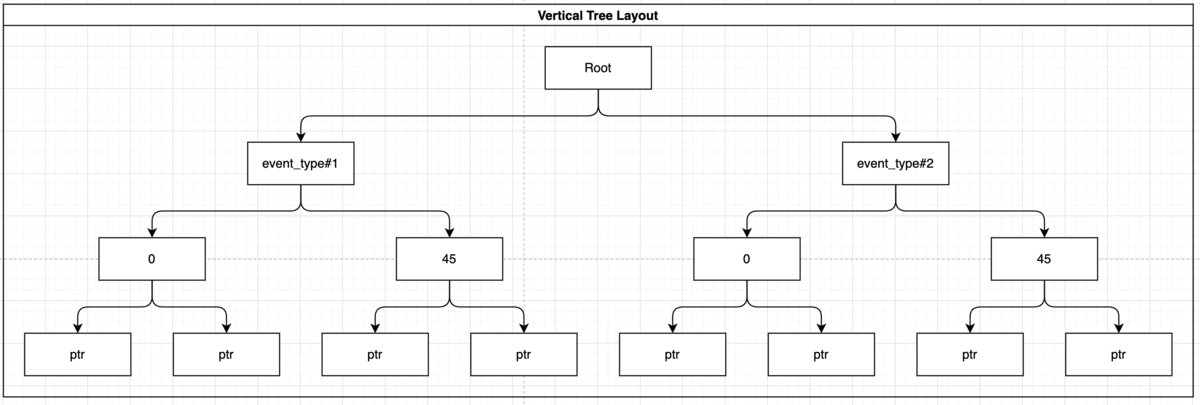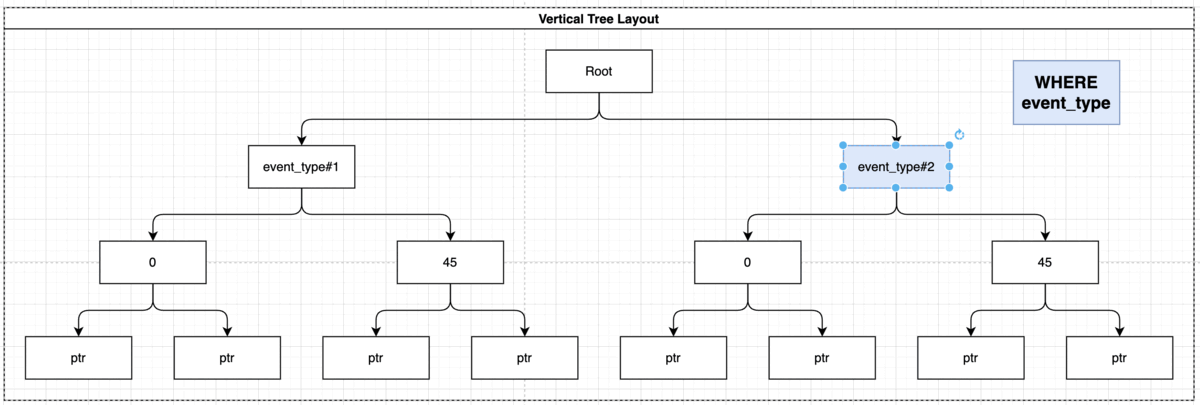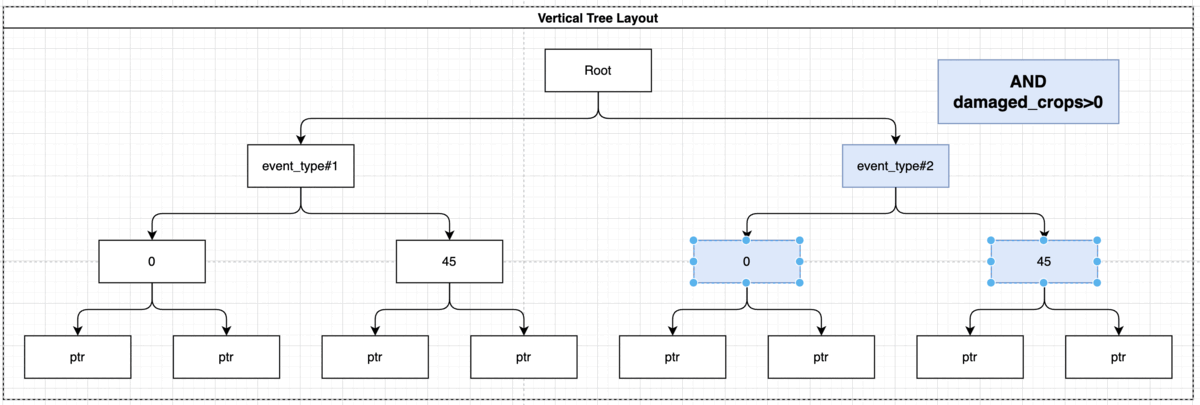
Indexing GROUP BY Statement
Let’s say we want to retrieve the states on which previous query happened on, so we’ll want to run this query:
SELECT state FROM weather
WHERE event_type = 'Winter Storm' AND damage_crops > 0
GROUP BY state;
Let’s run this query with EXPLAIN ANALYZE:
Group (cost=118.12..118.16 rows=7 width=9) (actual time=22.800..22.900 rows=3 loops=1)
Group Key: state
-> Sort (cost=118.12..118.14 rows=8 width=9) (actual time=22.600..22.700 rows=11 loops=1)
Sort Key: state
Sort Method: quicksort Memory: 17kB
-> Seq Scan on weather (cost=0.00..118.00 rows=8 width=9) (actual time=0.200..21.700 rows=11 loops=1)
Filter: (((damage_crops)::text > '0'::text) AND ((event_type)::text = 'Winter Storm'::text))
Rows Removed by Filter: 1189
Planning Time: 68.300 ms
Execution Time: 27.400 ms
(10 rows)
The planner will need to load all of the data to the memory and sort all of the data by state, then for each state it’ll need to filter out by our WHERE statement.
In order to make things faster we’ll need to index the parameter in the following way:
CREATE INDEX idx_storm_crop ON weather (state, event_type, damage_crops);
This way the engine does not need to fetch all of the data and sort it by itself, because the index holds the data in grouped way:
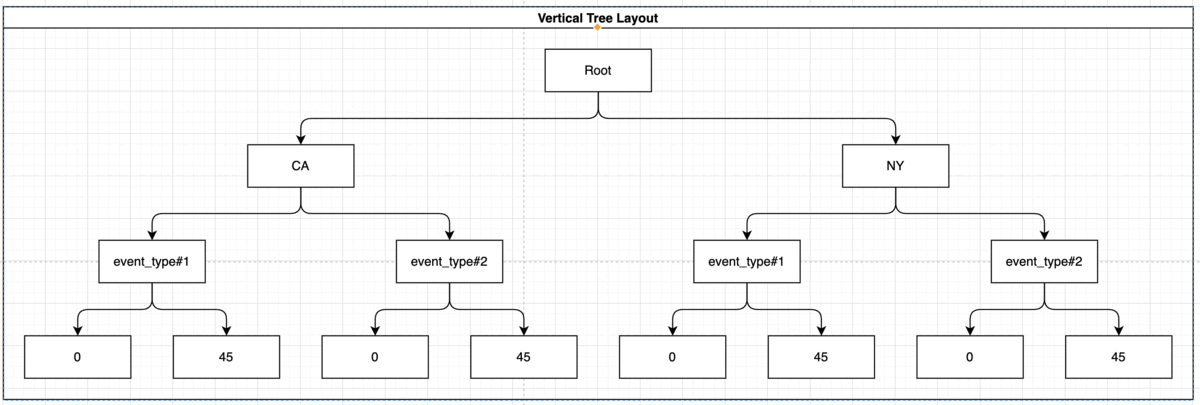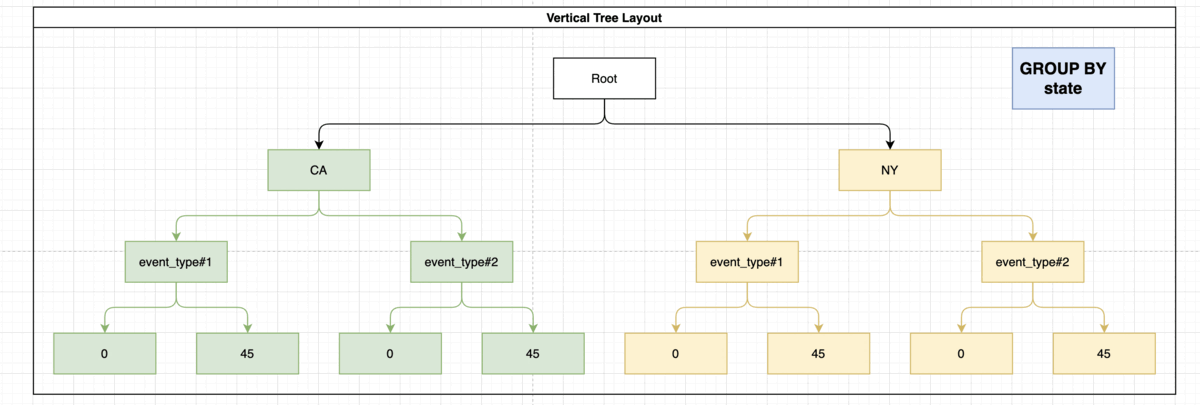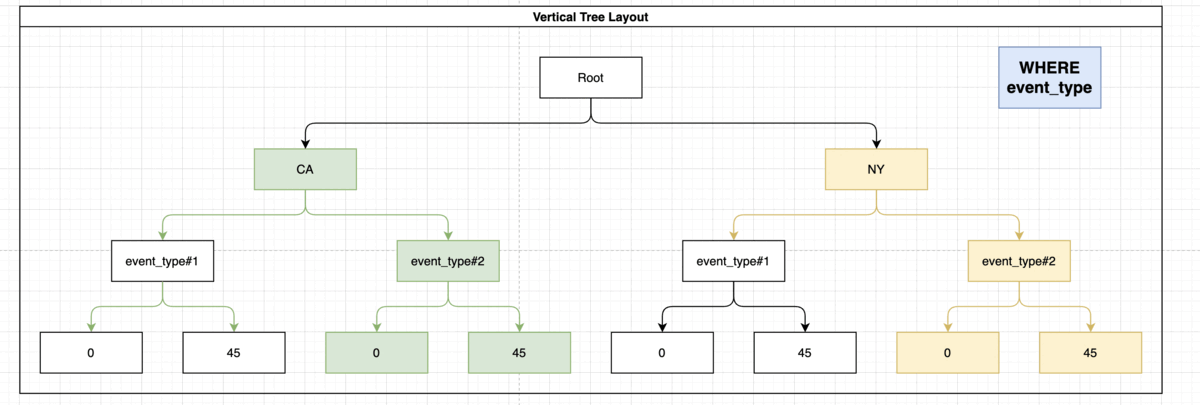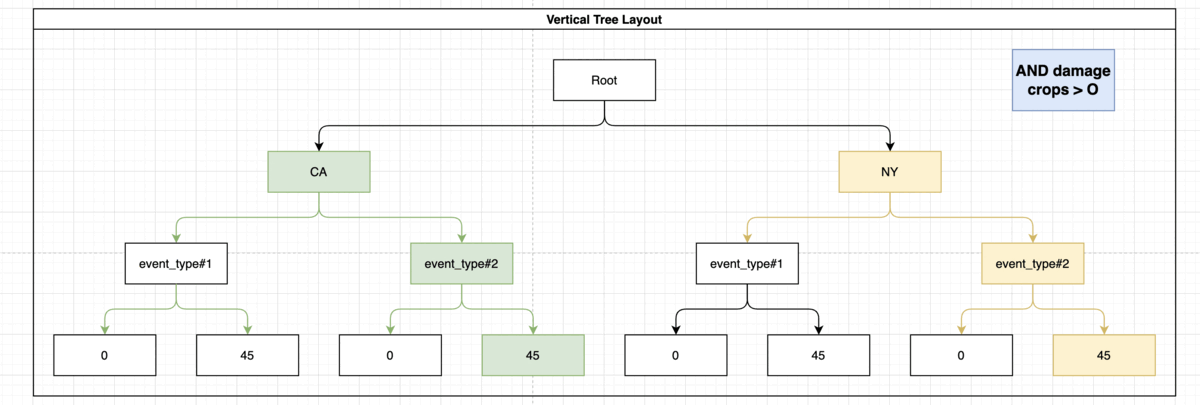
Indexing ORDER BY, LIMIT, OFFSET Statement
Let’s say we want to retrieve all of the events, ordered by the states and paginated, and let’s say we want to retrieve the 5th page of 100 events:
SELECT state FROM weather
ORDER BY state
OFFSET 500
LIMIT 100;
For this purpose we’ll want to use the previous index! Because Postgres BTREE is supporting node traversal, let’s take a look:
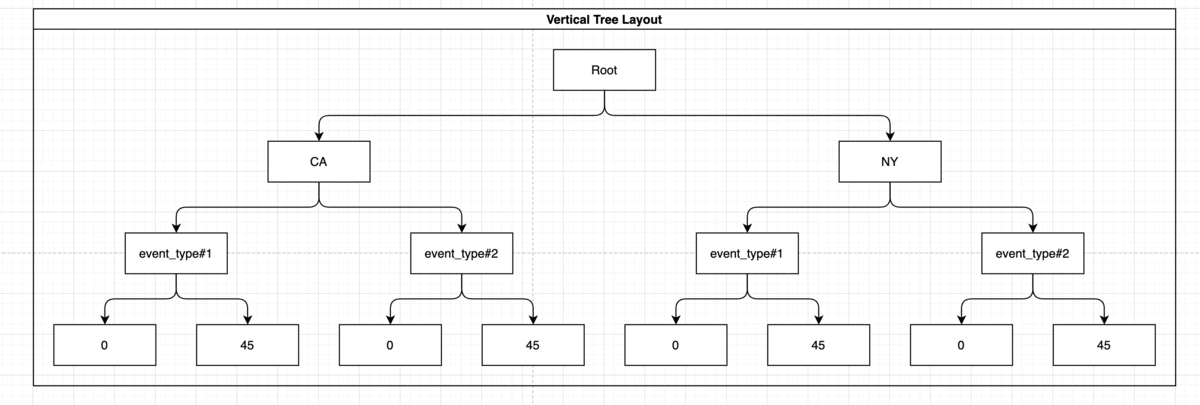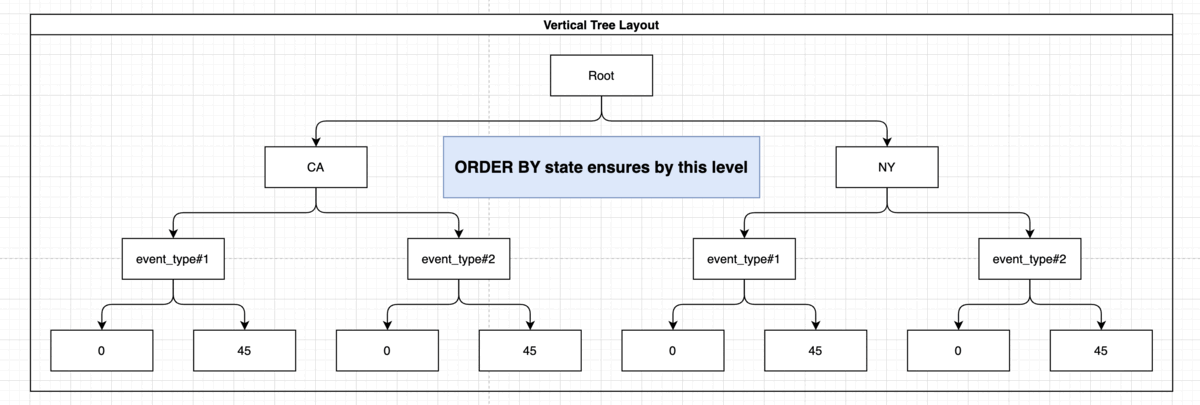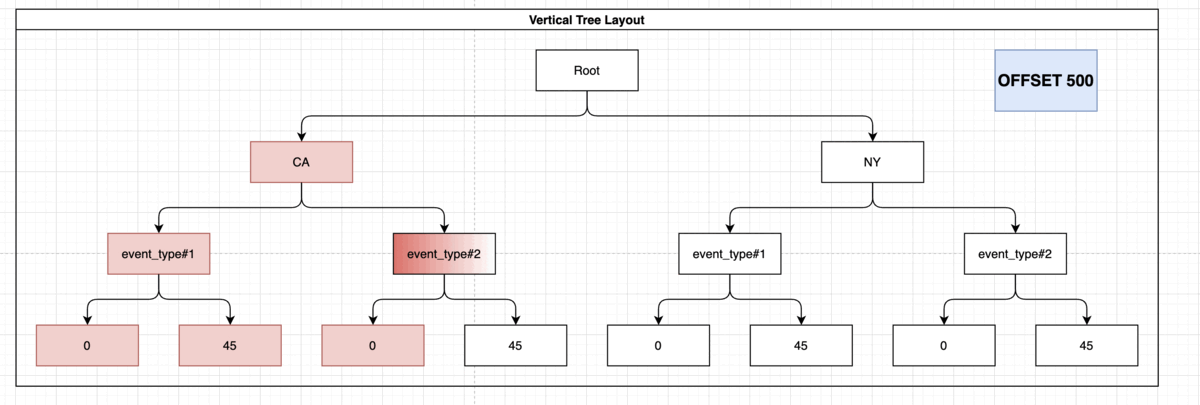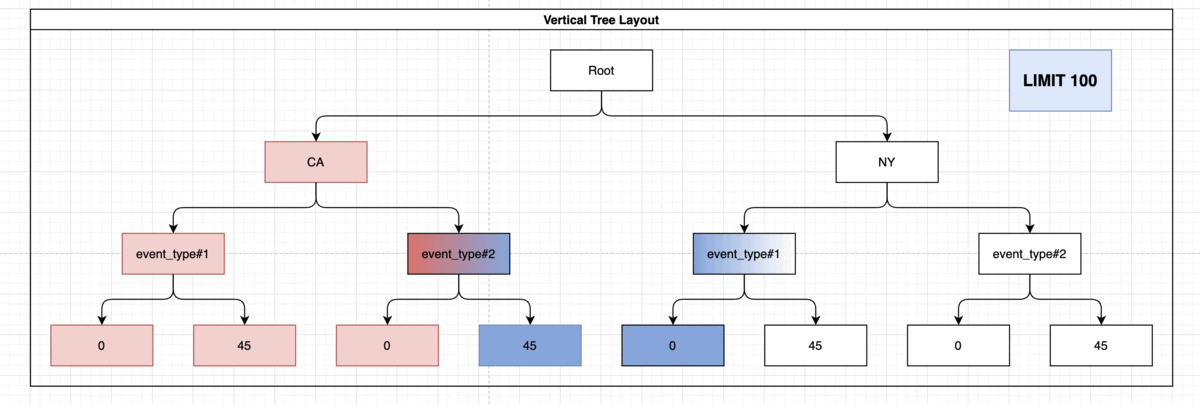
Note: The presence of “event_type” and the damage_crops on the index didn’t help you here but it also didn’t interfere with the usage of the index. This index might come in handy if you’d want to run more elaborate queries such as:
SELECT state FROM weather
WHERE event_type = 'Winter Storm' AND damage_crops > 0
ORDER BY state
OFFSET 500
LIMIT 100;
You can also create more complex indexes and combine different strategies into your queries.
Optimization Considerations
- EXPLAIN ANALYZE: Always use this command to understand how your queries are being executed and to identify potential bottlenecks.
- Test on Large Data Sets: Index performance can vary significantly with data volume. Test your queries on large data sets to simulate real-world scenarios.
- Check Edge Cases: Ensure your queries handle edge cases gracefully. Sometimes, certain inputs can lead to unexpected performance issues.
Resources for Further Learning
- Postgres Readme: For more in-depth information, deep dive into Postgres’s official readme here.
- Playground: Practice working with B-tree indexes using the interactive playground available here.
- Plan Explanation: Understand the PostgreSQL execution plan operations from this detailed resource: use-the-index-luke.com.
Conclusion
PostgreSQL indexes are essential tools for enhancing query performance in database management systems. By understanding the types of indexes available, their functionalities, and optimization techniques, you can make informed decisions on when and how to utilize them effectively. Always remember to analyze query execution plans, test on large data sets, and consider edge cases to ensure your database performs optimally.